第五章 声画驾驭——AI 音频与视频创作
本章摘要: 曾经,制作一段高质量的视频需要一支团队:编剧、摄像、灯光、剪辑、配音、配乐。现在,有了 AI,一个人就是一个剧组。本章将教会读者如何用 AI 生成音乐、克隆声音、制作数字人视频,并把这些技能串联起来,实现全流程的自动化内容创作。
知识图谱
导言:人人都是总导演
文字和图像之外,音频与视频是信息传播最具感染力的形式。一段配乐恰当的短视频、一个数字人播报的课程介绍——这些过去需要专业团队才能完成的工作,如今借助 AI 工具链,一个人就能完成从脚本到成片的全流程。
在短视频时代,“视频力”已经成为和写作力同等重要的表达能力。以前,你的创意可能卡在”我不会画分镜”、“我声音不好听”、“我剪辑软件太难学”上。现在,AI 帮你把这些门槛统统推平——不想出镜?用数字人;不会配乐?用 Suno 生成;不会剪辑?用剪映一键成片。你唯一需要做的,就是像总导演一样,告诉 AI 你要讲什么故事、要什么氛围、要传达什么情感。
但技术门槛的降低也带来一个新问题:当人人都能做视频时,什么才是真正的竞争力?答案是叙事能力——用画面讲故事的能力。工具可以帮你生成画面、配上音乐、合成语音,但”先讲什么、后讲什么、在哪里制造悬念、在哪里释放情绪”,这些叙事节奏的把控仍然是人的功夫。短视频时代的注意力只有前 3 秒,能不能抓住观众,靠的不是特效,而是对人心的理解。
本章将从 AI 音频创作入手,介绍音乐生成和语音合成的基本操作;然后进入 AI 视频制作,学习数字人生成和短视频制作的工作流;最后通过一个全流程综合实战,体验”一人即团队”的 AI 协同创作模式。
学习目标
完成本章学习后,读者将能够:
- 操作 Suno 生成原创背景音乐,并能通过元标签控制歌曲结构;
- 应用 语音合成(TTS)技术,制作情感丰富的配音或克隆自己的声音;
- 制作 数字人口播视频,实现”不露脸也能出镜”;
- 构建 “文案 → 语音 → 画面 → 剪辑”的全自动视频生产工作流;
- 辨识 Deepfake(深度伪造)技术的风险,树立正确的音视频伦理观。
5.1 AI 音频创作
一段合适的背景音乐、一个逼真的 AI 配音——音频是内容创作中常被忽视却至关重要的环节。
一、为什么音频很重要
可能觉得,做内容主要靠文字和画面,音频只是”锦上添花”。但实际上,音频对信息传达的影响远超想象。
心理学研究表明,人类对声音的情绪反应比视觉更快。一段视频如果去掉背景音乐,感染力会下降 40% 以上。想想刷短视频的体验——很多时候,是背景音乐先”抓住”了注意力,然后才开始看画面内容。
微实验:同一画面,不同配乐
不妨做一个简单的思想实验:想象一段 30 秒的校园航拍画面——操场、教学楼、林荫道。如果配上《步步高》,画面立刻变成充满活力的招生宣传片;换成大提琴独奏的《天鹅》,同样的画面瞬间变成毕业季的伤感回忆。画面没有变,变的只是声音——但观众感受到的”故事”完全不同。这说明,声音不只是画面的附属品,它本身就在”讲故事”。理解这一点,才能真正用好 AI 音频工具:生成的不仅是声音,更是情绪。
AI 音频工具的出现,让普通人也能快速制作专业级的音频内容。不需要会乐器、不需要录音棚、不需要专业配音员——只需要描述想要的效果,AI 就能帮助生成。
二、AI 音乐生成:Suno 的使用方法
Suno 是目前最受欢迎的 AI 音乐生成工具之一,用户只需输入文字描述,即可生成包含人声演唱的完整歌曲。2026 年初,Suno 推出了 Studio 1.2 版本,新增多轨编辑、变拍号支持(6/8、7/8 等)和 MIDI 导出功能,已从”玩具”进化为可用于专业音乐制作的生成式音频工作站,全球用户近 1 亿。
基本操作流程:
- 访问 Suno 官网(suno.com),注册并登录;
- 点击”Create”进入创作界面;
- 选择创作模式:
- 简单模式:直接输入一段文字描述(如”一首轻快的校园民谣,关于毕业季的回忆”),AI 自动生成歌词和旋律;
- 自定义模式:分别输入歌词(Lyrics)和风格标签(Style of Music),对生成结果进行更精细的控制。
- 点击生成,等待约 30 秒即可获得两个版本的完整歌曲。
风格控制关键词:
表5-1 Suno音乐风格控制关键词
| 风格类型 | 关键词示例 |
|---|---|
| 流行 | Pop, Synth-pop, Indie pop |
| 民谣 | Folk, Acoustic, Singer-songwriter |
| 电子 | Electronic, Lo-fi, Chillwave, EDM |
| 古典 | Classical, Orchestral, Piano solo |
| 中国风 | Chinese style, Guzheng, Erhu, Pentatonic |
| 氛围 | Ambient, Cinematic, Meditation |
提示词示例:
Style: Acoustic folk, warm, nostalgic
Lyrics:
[Verse]
九月的风吹过操场
书包里装满了阳光
[Chorus]
那些年我们一起走过的路
每一步都算数实操演示:用 Suno 为校园活动生成一首主题曲
第 1 步:打开 Suno(suno.com),登录后点击”Create”,切换到自定义模式(Custom)。
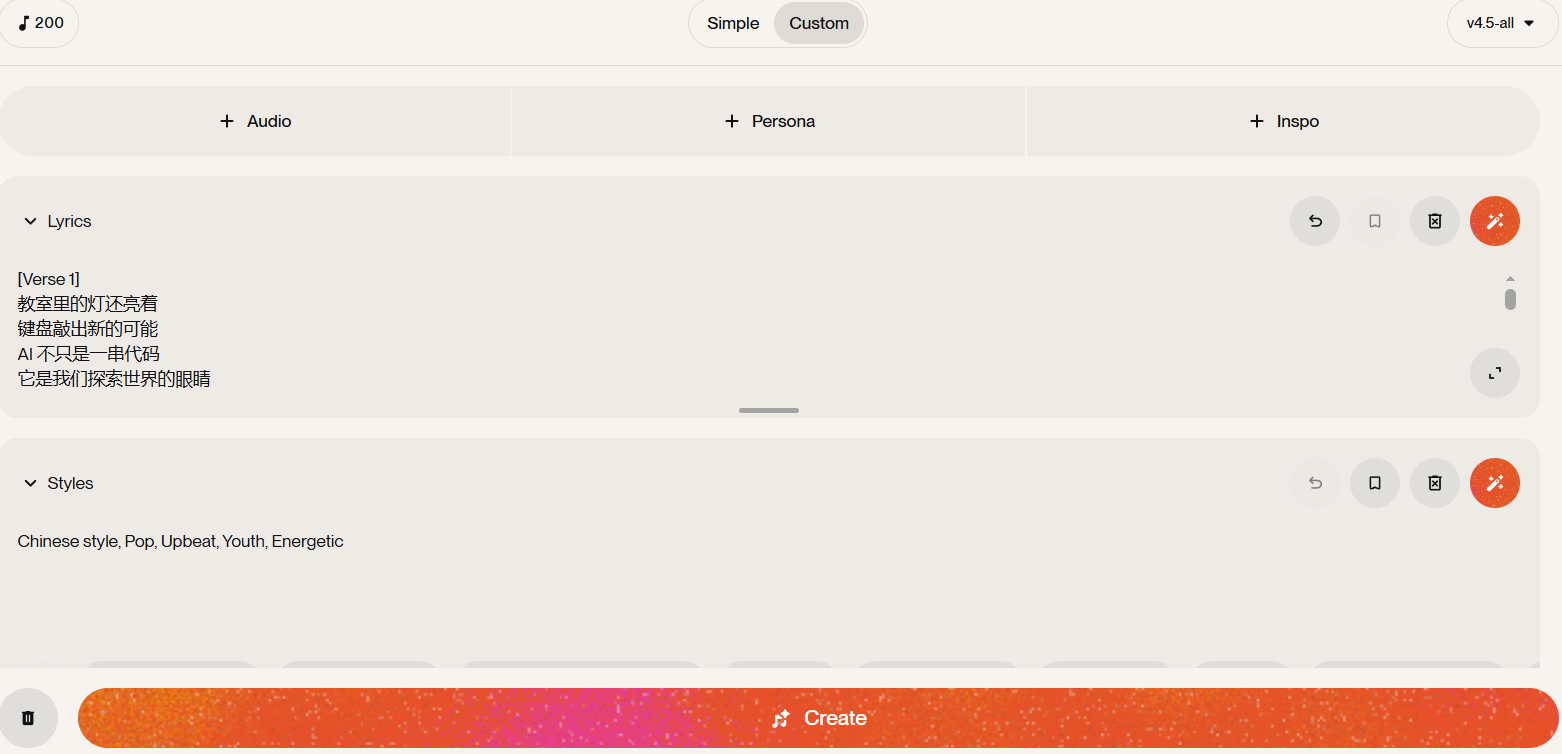
第 2 步:在”Style of Music”栏输入风格标签:
Chinese style, Pop, Upbeat, Youth, Energetic第 3 步:在”Lyrics”栏输入歌词:
[Verse 1]
教室里的灯还亮着
键盘敲出新的可能
AI 不只是一串代码
它是我们探索世界的眼睛
[Chorus]
用智慧点亮未来
每一次提问都是起跑线
用 AI 打开新世界
我们的故事才刚刚开始
[Verse 2]
操场上的风带着期待
屏幕里的世界无限宽广
从文字到画面到声音
每一步都有 AI 在身旁
[Chorus]
用智慧点亮未来
每一次提问都是起跑线
用 AI 打开新世界
我们的故事才刚刚开始第 4 步:点击”Create”,等待生成。Suno 会输出两个版本,可以试听后选择更满意的一个。
第 5 步:点击歌曲右侧的下载按钮,保存为 MP3 文件。
歌词写作技巧:
使用 [Verse]、[Chorus]、[Bridge] 等标签标注歌曲结构,AI 会据此安排旋律变化;
每行歌词控制在 10—15 个字,过长会导致演唱节奏不自然;
如果对生成结果不满意,可以微调风格标签——例如把”Upbeat”改为”Ballad”,整首歌的节奏就会变慢。
三、语音合成与声音克隆
语音合成(TTS)
语音合成(Text-to-Speech)是将文字转换为语音的技术。日常生活中随处可见它的身影——手机导航的语音播报、智能音箱的回答、短视频里的 AI 旁白,背后都是 TTS 技术。
技术原理:从”机器人腔”到”真人感”
早期的语音合成听起来像”机器人说话”,因为它只是把预录的音素片段拼接在一起。现代 AI 语音合成则完全不同,它的工作流程是:
输入文本 → 文本分析(分词、标注语调)→ 声学模型(生成声音特征)
→ 声码器(将特征转换为音频波形)→ 输出语音其中,声学模型是核心。它通过学习大量真人语音数据,掌握了语调起伏、停顿节奏、情感表达等规律。这就是为什么现在的 AI 配音听起来越来越像真人——它不是在”拼字”,而是在”说话”。
推荐工具与操作:
表5-2 主流AI配音工具对比
| 工具 | 特点 | 适用场景 |
|---|---|---|
| 讯飞智作 | 中文音色丰富,支持情感调节 | 有声读物、课件配音 |
| 通义听悟 | 语音转文字 + 多语种翻译 | 会议记录、字幕生成 |
| 剪映 AI 配音 | 内置于视频编辑器,操作便捷 | 短视频旁白 |
讯飞智作操作要点:
- 选择音色:根据内容风格选择合适的主播音色(新闻播报、情感故事、儿童读物等);
- 输入文本:粘贴需要配音的文案;
- 细节调整:
- 停顿控制:在句子之间插入停顿(0.3—1 秒),模拟真人呼吸节奏;
- 语速调节:全局调整主播语速,或选中特定句子进行局部变速;
- 多音字校正:手动标注多音字的正确读音。
实操演示:用讯飞智作为一段课程介绍配音
第 1 步:打开讯飞智作(peiyin.xunfei.cn),注册并登录,点击”开始创作”。
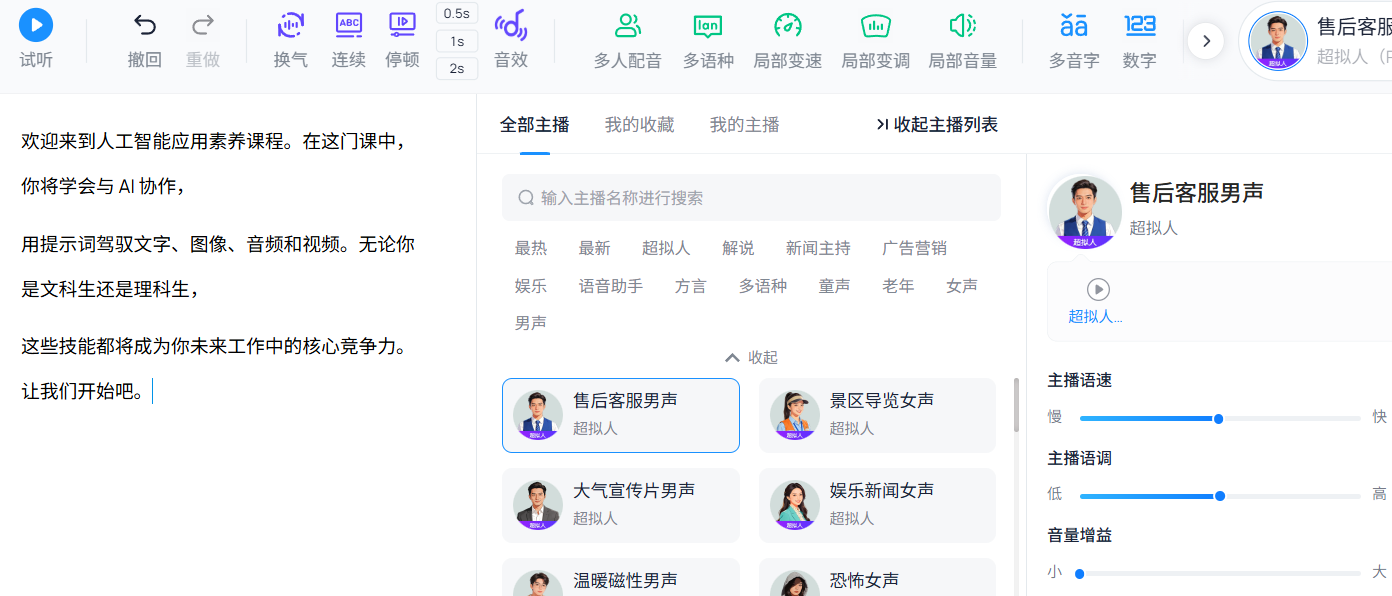
第 2 步:在文本编辑区粘贴以下文案:
欢迎来到人工智能应用素养课程。在这门课中,你将学会与 AI 协作,
用提示词驾驭文字、图像、音频和视频。无论你是文科生还是理科生,
这些技能都将成为你未来工作中的核心竞争力。让我们开始吧。第 3 步:在左侧音色列表中,选择”知性女声”或”沉稳男声”等适合教学场景的音色。点击试听,确认音色符合预期。
第 4 步:微调细节——选中”让我们开始吧”这句话,将语速调慢 10%,并在前面插入 0.5 秒停顿,营造”引导感”。
第 5 步:点击”合成”,试听完整音频。满意后点击”下载”,保存为 MP3 文件。
效果对比: 同一段文案,选择”新闻播报”音色会显得正式严肃,选择”温柔女声”则更亲切轻松。可以根据内容的使用场景选择最合适的音色。
声音克隆
声音克隆技术可以通过少量录音样本(通常 30 秒至 1 分钟),学习特定人的音色、语调和说话习惯,从而合成具有个人特征的语音。
技术原理简述:
录音样本 → 提取声纹特征(音色、语调、节奏)
→ 训练个性化语音模型 → 输入新文本 → 生成该人声音的语音安全提醒:声音克隆技术在带来便利的同时,也存在被滥用的风险(如电信诈骗中伪造亲友声音)。使用时应遵守法律法规,不得未经授权克隆他人声音。
思辨时刻:当逝者的声音被”复活”
声音克隆的伦理边界远不止防诈骗这么简单。2024 年,已有商业公司推出”数字永生”服务——用逝者生前的录音训练语音模型,让家属可以继续”听到”亲人的声音。这引发了一个深刻的问题:用 AI 克隆一位去世亲人的声音,是一种温暖的慰藉,还是对生命尊严的冒犯?如果逝者生前没有明确同意,后人是否有权”复活”他的声音?这些问题没有标准答案,但值得每一个技术使用者认真思考——技术的边界,往往就是人性的边界。
技术的善意:AI 音频在无障碍领域的应用
AI 语音合成不只是内容创作的效率工具,它正在为特殊群体打开新的窗口。语音合成可以为视障人士实时”朗读”网页、书籍和路标信息;声音克隆技术可以帮助因疾病失去声音的患者重新”开口说话”;AI 配音让小语种的教育资源得以快速翻译和传播。当我们学习这些工具时,不妨多想一步:除了让自己的内容更酷,这项技术还能为谁带来帮助?
拓展任务·美育融合:绘本配乐与校园广播
完成以下任一任务: 1. 绘本配乐:选择一个儿童绘本故事,使用 AI 语音合成工具生成旁白配音,再用 Suno 生成一段匹配故事氛围的背景音乐; 2. 校园广播音频:撰写一段 3 分钟的校园广播稿,使用 AI 配音工具生成播报音频,并添加片头音乐和背景音效。
5.2 AI 视频制作
不会拍摄、不会剪辑、不想出镜——这些曾经的”硬门槛”,正在被 AI 视频工具逐一消除。
一、视频叙事基础:好视频的底层逻辑
在学习 AI 视频工具之前,需要先理解一个关键问题:什么样的视频能吸引人看完?
无论是 30 秒的短视频还是 10 分钟的微课,好视频都遵循一个基本结构——“钩子—内容—行动”三段式:
表5-3 短视频”钩子—内容—行动”三段式结构
| 阶段 | 作用 | 时长占比 | 技巧 |
|---|---|---|---|
| 钩子(Hook) | 前 3 秒抓住注意力 | 5%—10% | 提问、悬念、反常识 |
| 内容(Body) | 传递核心信息 | 80%—85% | 分点叙述、节奏变化 |
| 行动(CTA) | 引导观众下一步 | 5%—10% | 关注、点赞、评论 |
钩子的常用写法:
提问式:“你知道 AI 一分钟能写多少字吗?”
反常识式:“90% 的人都在错误地使用 AI。”
场景式:“凌晨两点,论文还没写完……”
理解了这个结构,在使用 AI 生成脚本时,就能在提示词中明确要求”开头设置悬念”“结尾加行动号召”,生成的内容会更有吸引力。
“钩子—内容—行动”不只属于短视频。这套叙事逻辑在许多场景中同样有效:一场演讲的开头需要”钩子”来抓住听众;一封求职信的首段需要”钩子”让HR继续读下去;甚至给小朋友讲绘本,也需要用悬念式的开头吸引注意力。掌握这个结构,获得的不只是写脚本的技巧,而是一种通用的叙事思维能力。
二、数字人生成:让 AI 代替真人出镜
数字人(Digital Human)是通过 AI 生成的虚拟人物形象,能够根据输入的文本自动生成口播视频,解决”真人出镜难”的问题。
主流工具对比:
表5-4 主流数字人生成工具对比
| 工具 | 特点 | 适用场景 |
|---|---|---|
| HeyGen | 多语种支持,形象逼真 | 跨语言营销视频、产品介绍 |
| 剪映(CapCut) | 免费,数字人形象丰富,与即梦同属字节生态 | 口播教学、知识科普、企业宣传 |
| 闪剪 | 支持形象克隆,模板丰富 | 直播带货、知识分享 |
数字人视频制作流程:
- 形象选择或克隆:
- 使用平台提供的预设数字人形象;
- 或上传一段 30 秒至 1 分钟的真人视频(正面、光线均匀),训练专属数字人分身。
- 输入文案:将 DeepSeek 生成的口播文案粘贴到编辑区;
- 配置模板:选择背景模板(演播室、办公室、节日主题等),调节数字人大小和位置;
- 生成与导出:系统自动驱动数字人的口型和表情,生成完整的口播视频。
实操演示:用剪映制作一段课程欢迎视频
第 1 步:打开剪映专业版(PC 端或网页版 capcut.cn),注册并登录。在首页选择”数字人视频”功能入口。
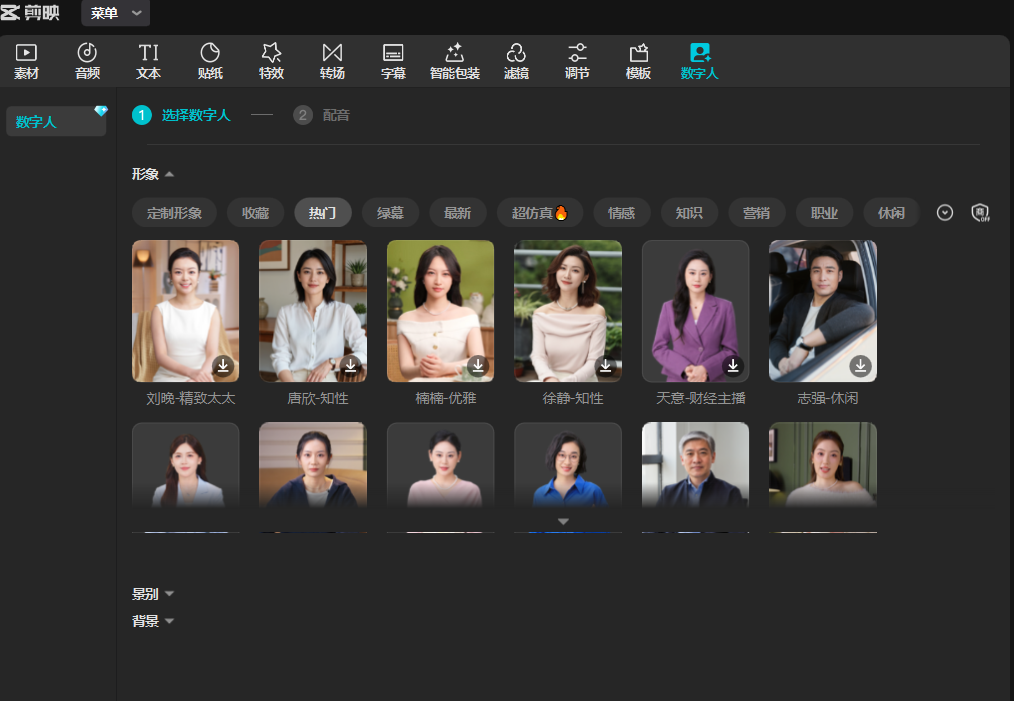
第 2 步:在数字人形象库中浏览不同分类(如”职场”“教育”“日常”等),选择一个适合教学场景的形象。剪映提供上百个预设数字人形象,也支持上传个人照片或短视频生成专属数字人分身。
第 3 步:在文案输入区粘贴以下口播文案(可先用 DeepSeek 生成),并从 150 余种 AI 音色中选择合适的朗读声音:
同学们好,欢迎来到人工智能应用素养课程。
在接下来的学习中,我们将一起探索 AI 在写作、绘画、
音视频创作等领域的实际应用。
无论你的专业背景是什么,这些技能都将帮助你
在未来的工作中事半功倍。让我们开始这段旅程吧!第 4 步:选择背景模板(演播室、办公室等),点击”生成视频”,等待系统渲染。生成完成后预览效果——观察数字人的口型是否与文案同步,表情是否自然。
第 5 步:如果满意,点击”导出”保存为 MP4 文件。如果口型有偏差,可以尝试调整文案中的标点符号(句号会产生较长停顿,逗号停顿较短)。
常见问题:
数字人表情僵硬:尝试在文案中加入感叹号或问号,AI 会据此调整表情;
口型不同步:检查文案中是否有生僻词或英文缩写,替换为常用表达;
背景不合适:部分平台支持上传自定义背景图片。
三、短视频制作:从脚本到成片的 AI 工作流
制作一段短视频,传统流程需要编剧、摄影、剪辑等多个角色协作。借助 AI 工具链,一个人即可完成全流程。
推荐工作流:DeepSeek + 剪映 AI
DeepSeek 生成脚本 → 拆分为分镜表 → 剪映"AI 生成"创建图片与视频素材
→ 组合剪辑 → 添加配音和字幕 → 导出成片步骤 1:用 DeepSeek 生成分镜脚本
提示词示例:
请为"AI 改变校园生活"主题撰写一段 60 秒短视频的分镜脚本。
要求:
1. 以表格形式呈现,包含:镜号、时长、画面描述、旁白文案;
2. 共 6 个镜头,节奏由慢到快;
3. 开头用悬念吸引观众,结尾有行动号召。生成结果示例:
表5-5 AI辅助生成的60秒短视频分镜脚本示例
| 镜号 | 时长 | 画面描述 | 旁白文案 |
|---|---|---|---|
| 1 | 8s | 清晨校园全景,阳光洒在教学楼上 | “你有没有想过,五年后的校园会是什么样?” |
| 2 | 10s | 学生对着电脑与 AI 对话的特写 | “AI 正在悄悄改变我们学习的方式……” |
| 3 | 10s | 课堂上老师使用智能白板教学 | “智能备课,让每一堂课都量身定制” |
| 4 | 10s | 学生用手机拍照识别植物 | “走出教室,AI 就是你的随身百科” |
| 5 | 12s | 多个 AI 应用场景快速切换 | “写作、绘画、编程、数据分析……” |
| 6 | 10s | 学生微笑面对镜头 | “未来已来,你准备好了吗?” |
步骤 2:用剪映”AI 生成”创建素材
新版剪映已将原”图文成片”功能升级为 “AI 生成”,包含两个子功能:图片生成和视频生成,可以直接根据分镜脚本中的画面描述来创建所需素材。
子功能 1:图片生成
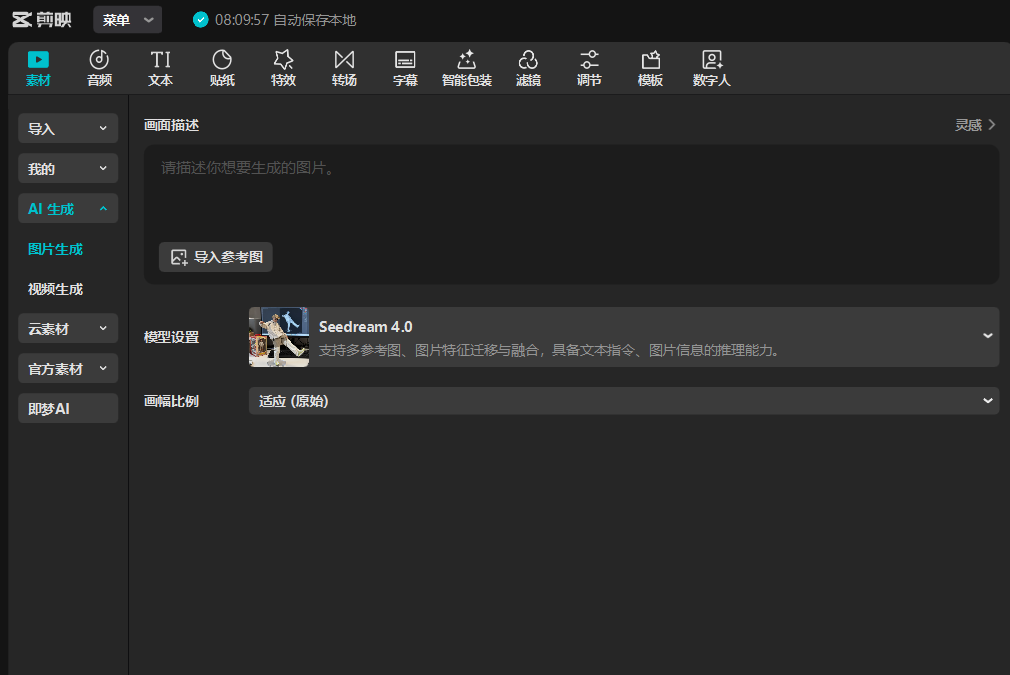
- 打开剪映专业版,进入”AI 生成”功能入口,选择”图片生成”;
- 在文本描述框中输入分镜脚本中的画面描述(如”清晨校园全景,阳光洒在教学楼上”);
- 如果希望生成的图片与某张参考图风格一致,可以点击”导入参考图”上传素材;
- 点击生成,从多张候选结果中选择最满意的一张。
子功能 2:视频生成
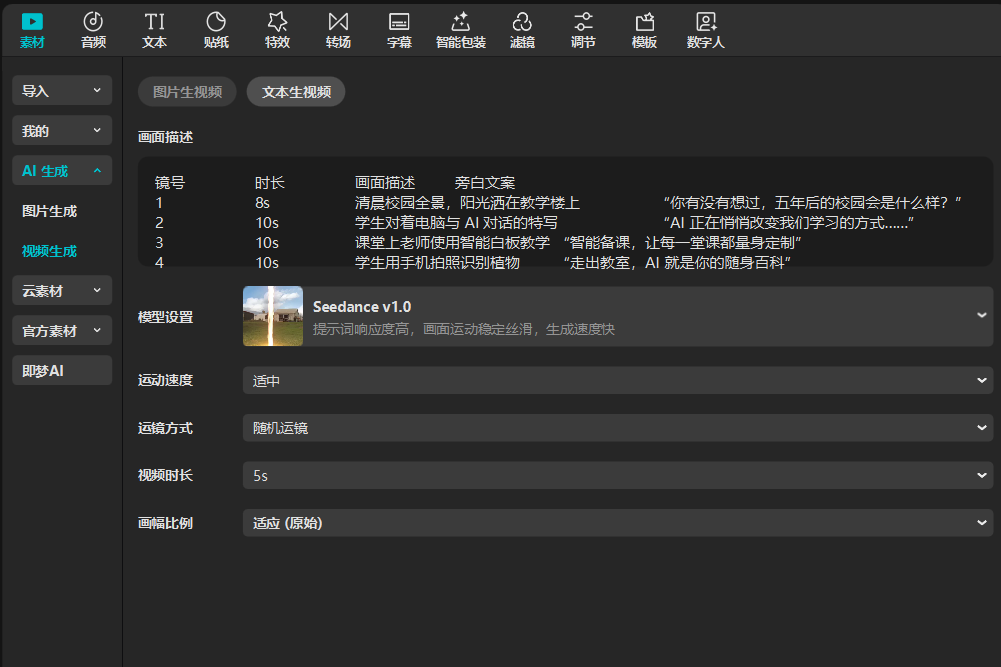
- 在”AI 生成”中选择”视频生成”;
- 支持两种模式:
- 文本生视频:直接输入画面描述文字,AI 自动生成对应的视频片段;
- 图片生视频:上传一张静态图片(可以是上一步 AI 生成的图片),AI 为其添加运动效果,生成动态视频。
- 根据分镜表逐个镜头生成素材,将生成的图片和视频片段依次拖入时间线。
步骤 3:后期调整
替换素材:对 AI 生成效果不满意的片段,可重新输入描述词生成替换;
参数微调:在右侧参数栏调整画面的缩放、不透明度,或字幕的字体和位置;
添加配音与字幕:将旁白文案整合为连贯文字,选择朗读音色(如”新闻女声”“活力男声”),系统自动对齐字幕与音频;
添加转场:在镜头之间添加合适的转场效果;
导出:检查无误后导出为 MP4 格式。
四、AI 视频生成大模型:从文字到电影级画面
数字人和短视频剪辑工具解决的是”有素材、怎么组装”的问题。而 AI 视频生成大模型要解决的是一个更根本的问题——没有素材,凭一段文字描述直接生成视频。
2024—2026 年间,视频生成大模型经历了爆发式发展:OpenAI 的 Sora、Runway Gen-3、Pika 等产品相继亮相。2026 年 2 月,字节跳动发布的 Seedance 2.0 将这一领域推向了新的高度——它不仅能生成画面,还能同步生成与画面严丝合缝的立体声音效,真正实现了”音画一体”的 AI 创作。
Seedance 2.0 的核心能力
表5-6 Seedance 2.0核心能力介绍
| 能力维度 | 说明 |
|---|---|
| 多模态输入 | 同时接受文字、图片(最多 9 张)、视频(最多 3 段)、音频(最多 3 段)作为输入 |
| 物理规律还原 | 精准呈现衣物重力感、光影折射、流苏甩动等物理细节 |
| 音画同步 | 集成双声道立体声,背景音乐、环境音效与画面动作精确对齐 |
| 导演级可控性 | 支持对表演、光影、运镜的精细调度,可按分镜脚本逐镜头生成 |
| 视频延长 | 支持”接着拍”功能,在已有视频基础上按提示词续拍新镜头 |
技术真相:Seedance 能”还原”重力和折射,并不意味着它理解牛顿定律或光学原理。它只是看过了数亿段视频后,总结出”东西掉下来应该是什么样”的概率分布。AI 模拟的是数据中的统计规律,而非物理定律本身——这是”数据驱动的现实感”,不是”理解现实”。认清这一点,有助于祛除对 AI”无所不能”的盲目崇拜。
体验地址:在豆包(doubao.com)中即可使用 Seedance 视频生成功能。 技术主页:https://seed.bytedance.com/zh/seedance2_0
提示词赏析:看看专业级 Prompt 长什么样
与文字对话中简短的提示词不同,视频生成的提示词往往需要像电影分镜脚本一样详细——描述镜头运动、人物动作、光影氛围、甚至声音设计。以下是 Seedance 2.0 官方展示的几个代表性提示词。
示例 1:竞技级双人花样滑冰(文生视频)
竞技级双人花样滑冰现场。开场低机位跟随冰刀滑行,冰屑与反光细节清晰。进入旋转段,男选手轴线微偏出现失误,旋转节奏短暂塌陷。女选手迅速调整重心,眼神冷静并示意”Stay with me”,主动引导男选手重新对齐节奏。随后无缝衔接托举动作,线条干净稳定。高潮为同步跳跃组合,空中姿态笔直,落冰果断,音画完美对齐。女选手身着深蓝花滑裙,男选手为竞技运动装。整体呈现从紧张失误到冷静完成比赛的完整叙事,体现顶级双人花样滑冰中的技术能力与心理强度。
这段提示词的写作技巧值得学习:它不仅描述了”画面是什么”,还构建了一个从失误到恢复的叙事弧线,并指定了镜头角度(低机位跟随)、细节特写(冰屑与反光)和情绪变化。
示例 2:穿越世界名画(多模态参考生成)
女孩打破次元壁,连续穿越多幅名画世界,保留真实质感,油画世界呈现 3D 高饱和度动画风格。她站在《星空》的旋转星空下神情激动;接着好奇看着情侣拥抱的画面;随后与《戴珍珠耳环的少女》一起自拍;紧接着在两名武士中间穿过;跑到《蒙娜丽莎》身旁,被摸头贴脸……对比度高,电影质感,转场丝滑无缝,人物鲜活。
这个案例展示了 Seedance 2.0 的”全能参考”能力——用户同时上传多张名画图片作为参考素材,模型理解每幅画的内容并让真人角色与之互动。
示例 3:武侠风格视听大片(文生视频 + 音效同步)
武侠风格视听大片,竹林里白衣剑客与蓑衣刀客对峙。镜头在两人之间缓慢推移,焦点在雨滴和剑柄之间切换,气氛压抑到极点,只能听见雨声。突然一道惊雷闪过,两人同时冲锋,侧拍镜头极速平移,捕捉泥浆飞溅的脚步。双兵相接瞬间画面切换为极慢动作,清晰展示刀剑震飞雨水形成的圆环激波,以及被剑气切断的竹叶。随后恢复常速两人背对背落地,蓑衣刀客的斗笠裂开,画面戛然而止。
注意这段提示词如何精确控制镜头语言(缓慢推移→极速平移→极慢动作→恢复常速)和声音设计(雨声→惊雷→刀剑撞击),这正是 Seedance 2.0 音画同步能力的最佳体现。
提示词的”导演视角”:一段提示词的结构拆解
以武侠大片的提示词为例,拆解其中不同层次的信息:
┌─────────────────────────────────────────────────┐
│ 【场景设定】 竹林里白衣剑客与蓑衣刀客对峙 │
├─────────────────────────────────────────────────┤
│ 【运镜指令】 缓慢推移 → 极速平移 → 极慢动作 │
│ → 恢复常速 → 画面戛然而止 │
├─────────────────────────────────────────────────┤
│ 【材质细节】 冰屑反光 / 泥浆飞溅 / 斗笠裂开 │
├─────────────────────────────────────────────────┤
│ 【声音设计】 雨声 → 惊雷 → 刀剑撞击 → 静默 │
├─────────────────────────────────────────────────┤
│ 【情绪节奏】 压抑 → 爆发 → 慢镜凝视 → 戛然而止 │
└─────────────────────────────────────────────────┘写视频提示词时,可以有意识地从这五个层次逐一填充,像导演写分镜一样构建画面。
从这些提示词中学到什么?
对比第三章学过的文字对话提示词,视频生成提示词有几个显著特点:
- 镜头意识:需要指定机位(低机位、侧拍)、运镜方式(跟随、推移、环绕)和景别变化;
- 时间线叙事:按时间顺序描述动作序列,而非静态场景;
- 多感官描写:不仅写画面,还写声音、光影、材质触感;
- 情绪节奏:通过动作快慢、镜头切换控制观众的情绪起伏。
这些技巧不仅适用于 Seedance,也适用于 Sora、Runway 等其他视频生成工具。掌握”像导演一样写提示词”的能力,将成为 AI 时代内容创作者的核心竞争力。
主线任务:制作一段 60 秒的课程介绍短视频
选择正在学习的一门课程,完成以下任务: 1. 使用 DeepSeek 生成分镜脚本(6—8 个镜头); 2. 使用剪映”AI 生成”功能(图片生成 + 视频生成)创建各镜头素材,组合为初版视频; 3. 进行至少 3 处手动调整(替换素材、修改字幕、添加转场等); 4. 导出最终成片。
拓展任务:微课片头制作
使用数字人工具制作一段 15 秒的微课片头,包含课程名称、教师介绍和欢迎语。
阅读材料:数字人直播——茶商用 AI 分身 7×24 小时直播的案例
2024 年,一位福建茶商尝试使用 AI 数字人进行直播带货。他录制了一段 1 分钟的真人视频用于训练数字人形象,然后将产品介绍话术输入系统,数字人便能 7×24 小时不间断直播。据报道,该数字人直播间的月均销售额达到了真人直播间的 60%—70%,而人力成本几乎为零。
这一案例展示了数字人技术在商业领域的巨大潜力,但也引发了思考:当消费者发现与自己互动的”主播”其实是 AI 时,他们会作何感想?商家是否有义务告知消费者正在与数字人交流?
5.3 全流程自动化综合实战
当文字、图像、音频、视频的 AI 工具串联起来,一个人就能完成过去需要整个团队才能交付的工作。
一、综合案例:从访谈录音到演讲稿的全闭环
假设参加了一场行业访谈,需要将录音整理为一份完整的汇报材料。传统流程需要多人协作,而借助 AI 工具链,一个人即可完成全部环节。
全流程工具链:
表5-7 从访谈录音到演讲稿的AI工具链
| 步骤 | 任务 | 工具 | 输出 |
|---|---|---|---|
| 1 | 录音转文字 | 通义听悟 | 带说话人标注的文字稿 |
| 2 | 提炼要点 | DeepSeek | 结构化的要点摘要 |
| 3 | 生成 PPT 大纲 | DeepSeek | 分页大纲与备注 |
| 4 | 制作 PPT | AiPPT | 完整演示文稿 |
| 5 | 撰写演讲稿 | DeepSeek | 配合 PPT 的口播文案 |
| 6 | 生成配音 | 讯飞智作 / 剪映 | 演讲音频 |
操作示范:
下面以”采访一位创业校友”为场景,演示每个步骤的具体操作。
步骤 1:录音转文字
打开通义听悟(tingwu.aliyun.com),点击”上传音视频”,选择采访录音文件(支持 MP3、WAV、MP4 等格式)。
上传完成后,系统会自动进行语音识别。等待处理完毕,会看到带有说话人标注的完整文字稿。点击”导出”,选择”文本格式”,复制全部内容。
步骤 2:用 DeepSeek 提炼要点
将文字稿粘贴到 DeepSeek,输入以下提示词:
以下是一段创业校友访谈的文字记录。请完成:
1. 提炼 5 个核心观点,每个观点用一句话概括;
2. 整理 3 条可引用的精彩原话(保留原文);
3. 归纳访谈中提到的关键数据(如融资金额、用户数等);
4. 用 3 句话总结这次访谈的核心主题。
[粘贴文字稿]DeepSeek 输出示例:
核心观点: 1. AI 工具让小团队也能做出大公司级别的产品; 2. 创业初期最重要的不是技术,而是找到真实的用户需求; 3. 大学期间的项目经历是最好的创业预演; 4. 融资不是目的,可持续的商业模式才是关键; 5. 失败的经验比成功的经验更有价值。
精彩原话: 1. “我们第一个产品失败了,但那次失败教会我的东西,比 MBA 课程还多。” 2. “不要等准备好了再开始,边做边学才是最快的成长方式。” 3. “AI 不会取代创业者,但会用 AI 的创业者会取代不会用的。”
步骤 3:生成 PPT 大纲
将提炼的要点发给 DeepSeek:
请根据以下访谈要点,生成一份 8 页的 PPT 大纲。
每页包含:页面标题、3 个要点、备注栏(演讲提示)。
第 1 页为封面,最后一页为总结与致谢。
[粘贴上一步的输出]步骤 4:制作 PPT
将生成的大纲导入 AiPPT 一键生成演示文稿(详见 3.4 节的操作流程)。
步骤 5:撰写演讲稿
请根据以下 PPT 大纲,为每页撰写 30 秒的演讲稿。
要求:口语化表达,每页之间有自然过渡,
总时长控制在 5 分钟以内。
开头用一个故事引入,结尾呼应开头。
[粘贴 PPT 大纲]步骤 6:生成配音
打开讯飞智作,将演讲稿粘贴到编辑区,选择”沉稳男声”或”知性女声”音色,调整语速为正常偏慢(适合演讲场景),合成并导出 MP3 文件。
二、跨平台内容转换
同一份素材,在不同平台需要不同的呈现形式。AI 可以帮助快速完成格式转换。
案例:抖音热点视频 → 小红书图文笔记
我有一段关于"大学生 AI 学习方法"的抖音短视频,
以下是视频的逐字稿。请将其转换为一篇小红书图文笔记:
1. 标题使用"数字型"公式(参考 3.3 节);
2. 正文 300 字以内,分 4 个要点,每个要点配 emoji;
3. 结尾设置互动问题;
4. 附 5 个话题标签。
[粘贴视频逐字稿]常见的跨平台转换路径:
表5-8 内容跨平台转换路径
| 原始内容 | 目标平台 | 转换要点 |
|---|---|---|
| 长视频 | 短视频平台 | 提取高光片段,添加字幕和节奏感 |
| 短视频 | 图文平台 | 提炼文字要点,配图排版 |
| 文章 | 播客/音频 | 改写为口语化表达,生成配音 |
| PPT | 短视频 | 逐页录屏或转为分镜脚本 |
思辨时刻:当无法分辨真假视频——Deepfake 的识别与伦理
Deepfake(深度伪造)技术利用生成对抗网络(GAN),可以将一个人的面部特征”贴”到另一个人的视频中,生成高度逼真的换脸视频。
如何识别 Deepfake 内容?
观察以下细节破绽: 1. 眨眼频率:伪造视频中人物的眨眼频率往往异常(过快、过慢或不眨眼); 2. 光影一致性:人脸的光影方向是否与背景环境光一致,边缘是否模糊; 3. 口型同步:口型是否与声音完美同步,牙齿细节是否自然; 4. 微表情与轮廓:表情是否僵硬,下巴、发际线等边缘是否有伪影。
现实案例:
2024 年,香港某跨国公司的财务人员收到”公司高管”的视频会议邀请。会议中,多位”高管”通过视频通话下达了转账指令。财务人员按指示操作,最终被骗走约 2 亿港元。事后调查发现,会议中的所有”高管”都是 AI 生成的 Deepfake 形象。
思考以下问题: 1. 在 AI 生成内容越来越逼真的今天,“眼见为实”这一常识是否还成立? 2. 平台是否有责任对 AI 生成的音视频内容进行标注?如何在技术上实现? 3. 如果有人用他人的照片和声音生成了虚假视频,应该如何维权?
本章小结
本章从 AI 音频创作入手,延伸至视频制作,最终通过全流程综合实战,展示了”一人即团队”的 AI 协同创作模式。技术门槛的降低使人人都能成为内容创作者,而叙事能力——用画面讲故事的能力——成为真正的核心竞争力。
| 小节 | 核心内容 | 关键概念 |
|---|---|---|
| 5.1 AI 音频创作 | 使用 Suno 生成原创音乐,掌握语音合成(TTS)技术制作配音或声音克隆 | Suno、语音合成(TTS)、声音克隆 |
| 5.2 AI 视频制作 | 制作数字人口播视频,学习视频叙事的”钩子—内容—行动”三段式结构 | 数字人、视频叙事、剪映 AI |
| 5.3 全流程自动化综合实战 | 构建”文案 → 语音 → 画面 → 剪辑”的全自动视频生产工作流 | 全流程工具链、自动化协作 |
工具帮助生成画面、配上音乐、合成语音,但叙事节奏的把控仍然是人的功夫。第二篇至此完结,下一篇将进入数据洞察与智能体搭建的进阶领域。
第五章 实践与练习
视频是时间的艺术。AI 帮你节省了制作的时间,是为了让你花更多时间去打磨故事。
一、选择题
- Suno 生成音乐时,以下哪种方式能更精确地控制生成结果?
- A. 在简单模式下输入一句话描述
- B. 在自定义模式下分别输入歌词和风格标签
- C. 同时上传一段参考音频
- D. 使用更长的文字描述
- 现代 AI 语音合成(TTS)听起来越来越像真人,核心原因是:
- A. 使用了更高采样率的音频格式
- B. 声学模型通过学习大量真人语音掌握了语调和节奏规律
- C. 直接拼接了真人录音片段
- D. 使用了更好的麦克风录制
- 短视频的”钩子—内容—行动”三段式结构中,“钩子”的作用是:
- A. 总结视频的核心观点
- B. 在前几秒抓住观众注意力
- C. 引导观众点赞关注
- D. 介绍视频的背景信息
- 以下哪项是识别 Deepfake 视频的有效方法?
- A. 检查视频的文件大小
- B. 观察人物的眨眼频率和光影一致性
- C. 查看视频的上传时间
- D. 检查视频的分辨率
二、简答题
请用自己的话解释 AI 语音合成(TTS)的工作流程,并说明它与早期”机器人腔”语音合成的本质区别。
在制作短视频时,为什么”钩子”(Hook)如此重要?请列举三种常用的钩子写法,并各举一个例子。
三、实操题
AI 音乐创作:使用 Suno,为所在学校的某个社团或活动创作一首主题曲。要求:使用自定义模式,自行撰写至少一段歌词(Verse)和一段副歌(Chorus),选择合适的风格标签,生成后记录使用的完整提示词。
短视频制作:选择一个感兴趣的主题(如”大学生必备的 3 个 AI 工具”),使用 DeepSeek 生成分镜脚本,再用剪映”AI 生成”功能创建素材并剪辑成片。要求:至少 6 个镜头,开头有钩子,结尾有行动号召。
Deepfake 辨别练习:在网络上搜索 3 个 AI 生成的人物视频(如数字人播报、AI 换脸视频),尝试用本章介绍的 4 个识别维度(眨眼频率、光影一致性、口型同步、微表情轮廓)逐一分析,记录观察结果。
人文创作(选做):用 AI 为家乡或学校制作一段 1 分钟的”治愈系情书”短视频。要求:用 Suno 生成一段温暖的背景音乐,用 TTS 录制一段深情的旁白,用剪映组合画面。重点不在技术炫技,而在于用镜头、音乐和文字表达对一个地方的真实情感。
参考答案(选择题):1-B 2-B 3-B 4-B
四、进阶挑战:虚拟数字人主播
背景:学校广播台想开设一个”午间 AI 播报”栏目。
任务:
- 形象:用即梦 AI 生成一个”极具亲和力”的虚拟主播形象(2D 二次元或 3D 写实均可)。
- 声音:用 TTS 工具为他/她匹配一个好听的声音。
- 播报:用 DeepSeek 生成一段 200 字的”校园新闻快讯”(包含天气、食堂菜谱、社团活动)。
- 合成:让数字人播报这段新闻(使用 D-ID 或 HeyGen 试用版)。
思考:相比真人主播,虚拟主播的优势是什么?(24小时在线、不念错字、多语言)。劣势是什么?(缺乏真实的情感连接)。
五、延伸阅读
- 伦理:了解”AI 换脸诈骗”的真实案例,提高防范意识
- 教程:剪映官方教程 —— 包含剪辑的所有基础逻辑(景别、蒙太奇、转场)