第六章 数据洞察——让数字开口说话
本章摘要: 在大数据时代,只有数据没有洞察,就等于守着金矿要饭。本章将教会读者如何利用 AI 成为数据分析师。无论是文科生还是理科生,都能通过 AI 轻松搞定复杂的 Excel 公式、自动生成可视化图表,甚至用 Python 代码挖掘数据背后的秘密。
知识图谱
导言:告别”表哥表姐”的苦日子
我们每天都在产生数据——考试成绩、体测记录、消费账单、社交互动。但数据本身只是一堆数字,只有经过分析和可视化,才能从中发现规律、支撑决策。
过去,数据分析是统计学和编程的专属领域。如今,AI 让这一切变成了自然语言交互——“帮我把这一列的日期格式统一一下”、“分析一下为什么这周的销售额下降了”、“用 Python 画一张带趋势线的散点图”。AI 就是你的全能数据助理,它不仅能干脏活累活(清洗数据),还能干脑力活(分析洞察)。
本章将从 AI 辅助的数据分析基础讲起,延伸到个性化方案定制,最后为有编程兴趣的同学提供 Python 数据分析的入门路径。
学习目标
完成本章学习后,读者将能够:
- 运用 AI 辅助 Excel 操作:自动写复杂公式(如 VLOOKUP)、清洗脏数据、生成数据透视表逻辑;
- 生成 数据分析报告:上传表格,让 AI 自动发现数据中的趋势、异常值和相关性;
- 定制 个性化方案:基于数据(如体测成绩、性格测试),用 AI 生成针对性的改进计划;
- 体验 Python 数据分析(进阶):理解 Pandas 和 Scikit-learn 的基本用法,运行简单的机器学习代码。
6.1 数据分析基础
一份杂乱的 Excel 表格,AI 能在几分钟内完成清洗、分析和可视化——前提是会”提问”。
一、为什么需要数据分析
有人可能觉得”数据分析”是统计学专业的事。但换个角度想:幼儿园老师观察孩子的身高体重曲线,判断发育是否正常;艺术生分析社交媒体的互动数据,决定下一组作品的风格方向;甚至你每天看天气预报决定穿什么衣服——这些说白了都是在”读数据”。数据不是冰冷的数字,而是现实世界的”数字孪生”,是理解世界的第二语言。区别只在于:有人读得懂,有人读不懂。
举个例子:班长需要统计全班同学的成绩,找出哪些科目的不及格率最高;社团负责人需要分析活动报名数据,判断哪种宣传渠道效果最好;创业团队需要分析用户反馈,决定下一步产品方向。这些场景都需要从数据中提取有价值的信息。
AI 工具的出现,大幅降低了数据分析的门槛。不需要精通 Excel 函数,也不需要会写代码——只要能清楚地描述分析需求,AI 就能帮助完成。
几个基础统计概念:
在让 AI 分析数据之前,需要了解几个常用的统计指标,这样才能看懂 AI 的输出结果:
表6-1 基础统计指标说明
| 指标 | 含义 | 通俗解释 |
|---|---|---|
| 均值(Mean) | 所有数据的算术平均 | “大家平均考了多少分” |
| 中位数(Median) | 排序后位于中间的值 | “排在正中间的同学考了多少分” |
| 标准差(Std) | 数据的离散程度 | “大家的成绩差距大不大” |
| 最大/最小值 | 数据的极端值 | “最高分和最低分是多少” |
小贴士:均值容易受极端值影响。比如一个班 30 人,29 人考了 80 分,1 人考了 20 分,均值是 78 分,但中位数是 80 分。中位数更能反映”大多数人”的水平。
数据陷阱:平均工资的谎言
一位亿万富翁走进一家只有 10 位普通工人的小酒馆,瞬间,这家酒馆的”人均资产”过亿。数字没有错,但结论荒谬——这就是均值的陷阱。现实中,当新闻报道”某城市平均月薪 1 万元”时,大多数人的真实感受可能是”被平均了”。如果换用中位数,数字可能只有 6000 元。同一组数据,选择不同的统计指标,讲出的”故事”截然不同。学会追问”这个数字用的是什么指标”,是数据素养的第一课。
二、AI 辅助数据分析的基本流程
无论数据来自哪里,AI 辅助分析通常遵循以下流程:
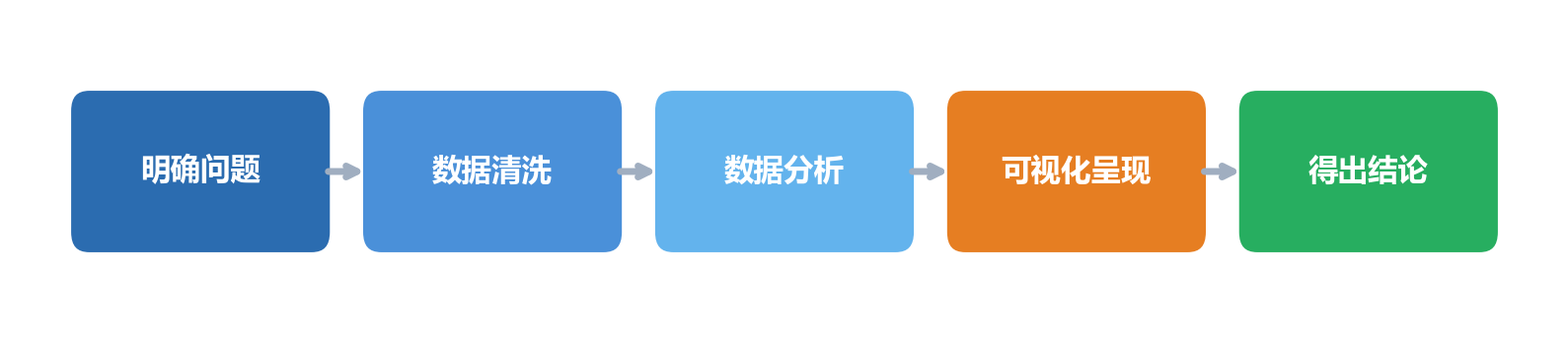
每个环节都可以借助 AI 工具来加速。
三、数据清洗:让”脏数据”变干净
真实世界的数据往往存在缺失值、重复项、格式不统一等问题。直接分析”脏数据”会导致错误的结论。
常见的数据质量问题:
表6-2 数据质量问题与AI辅助解决方式
| 问题类型 | 示例 | AI 辅助解决方式 |
|---|---|---|
| 缺失值 | 某些学生的成绩为空 | 让 AI 生成填充公式(均值/中位数填充) |
| 重复项 | 同一条记录出现两次 | 让 AI 生成去重公式或 VBA 脚本 |
| 格式不统一 | 日期格式混乱(2024/1/1 vs 1月1日) | 让 AI 生成格式转换公式 |
| 异常值 | 某学生成绩为 999 分 | 让 AI 识别并标记异常数据 |
提示词示例(数据清洗):
以下是一份班级成绩表的部分数据(粘贴数据)。请帮我:
1. 检查是否存在缺失值,并建议填充方案;
2. 检查是否存在重复记录;
3. 检查是否存在明显的异常值;
4. 给出用于清洗的 Excel 公式。四、用 AI 生成 Excel 公式
零基础也能跟上:下面会出现一些 Excel 公式,看不懂没关系——重点不是记住公式,而是学会”用自然语言告诉 AI 你想算什么”。你只需要把数据粘贴给 AI,用大白话描述需求,AI 会帮你生成公式并解释用法。
对于不熟悉 Excel 函数的用户,AI 可以根据自然语言描述直接生成公式。
常见场景与提示词:
表6-3 自然语言需求与AI生成Excel公式示例
| 需求描述 | AI 生成的公式 |
|---|---|
| “计算 B 列所有大于 60 分的平均值” | =AVERAGEIF(B:B,">60") |
| “统计 C 列中’优秀’出现的次数” | =COUNTIF(C:C,"优秀") |
| “如果 D 列大于 90 显示’A’,大于 80 显示’B’,否则显示’C’” | =IF(D2>90,"A",IF(D2>80,"B","C")) |
| “按班级分组计算各科平均分” | 数据透视表操作步骤 |
提示词模板:
我有一份 Excel 表格,列结构如下:[描述列名和数据类型]。
请帮我生成公式,实现以下功能:[描述需求]。
请同时说明公式的含义和使用方法。五、数据可视化:让数字”说话”
数据分析的结果需要通过可视化来直观呈现。AI 可以帮助选择合适的图表类型并生成代码。
图表类型选择指南:
视觉叙事的陷阱:同一组数据,用饼图展示会强调”各部分的占比关系”,用柱状图展示则强调”各项之间的大小差距”。如果某个班级的成绩只比其他班高 2 分,用柱状图并把纵轴起点设为 75 分,视觉上差距会被放大数倍;而如果纵轴从 0 开始,差距几乎看不出来。选择什么图表、如何设置坐标轴,本身就是一种”叙事立场”。学会读图,也要学会识破图表背后的”视觉修辞”。
表6-4 数据可视化图表类型选择指南
| 分析目的 | 推荐图表 | 适用场景 |
|---|---|---|
| 比较大小 | 柱状图 / 条形图 | 各班平均分对比 |
| 展示趋势 | 折线图 | 月度成绩变化 |
| 显示占比 | 饼图 / 环形图 | 各等级人数占比 |
| 分析分布 | 直方图 / 箱线图 | 成绩分布情况 |
| 展示关系 | 散点图 | 学习时长与成绩的关系 |
使用 Mermaid 生成简单图表:
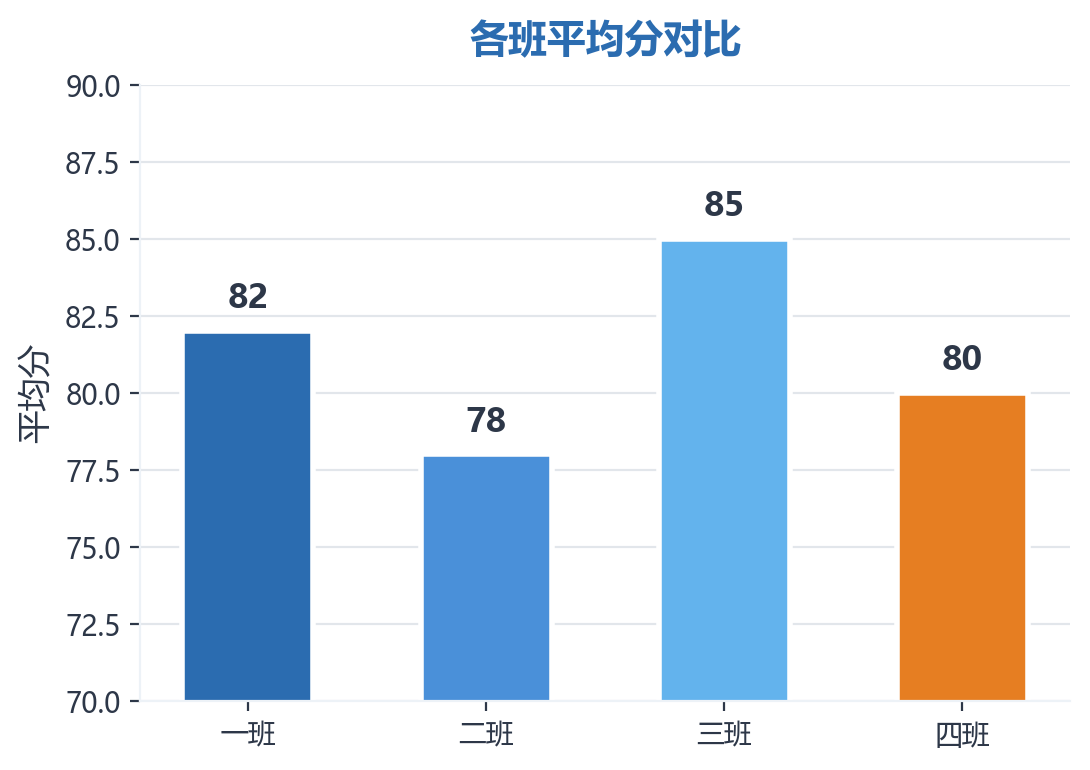
AI 可以直接生成 Mermaid 语法的图表代码,适合快速嵌入报告。
请根据以下数据生成一个 Mermaid 柱状图:
一班平均分 82,二班 78,三班 85,四班 80。AI 生成结果:
六、实操演示:用 DeepSeek 分析一份成绩数据
第 1 步:准备数据。假设有以下 10 名同学的期末成绩(语文、数学、英语):
姓名,语文,数学,英语
张三,85,92,78
李四,72,65,80
王五,90,88,95
赵六,68,,75
钱七,85,92,78
孙八,55,48,60
周九,78,82,85
吴十,92,95,90
郑十一,999,80,72
张三,85,92,78注意:这份数据故意包含了几个问题——赵六的数学成绩缺失、郑十一的语文成绩异常(999)、张三的记录重复。
第 2 步:将数据粘贴到 DeepSeek,输入提示词:

以下是一份班级期末成绩数据。请帮我完成:
1. 数据质量检查:找出缺失值、重复项和异常值;
2. 数据清洗建议:给出处理方案;
3. 基本统计分析:计算各科的均值、中位数、标准差;
4. 找出偏科严重的学生(某科与其他科差距超过 20 分)。DeepSeek 输出示例:
数据质量检查: - 缺失值:赵六的数学成绩为空 - 重复项:张三出现了 2 次,数据完全相同 - 异常值:郑十一的语文成绩为 999,明显超出合理范围
清洗建议: - 赵六的数学成绩:建议用其他科目的平均分(71.5)估算,或标记为待补录 - 张三的重复记录:删除其中一条 - 郑十一的语文 999 分:建议联系教务确认,暂时标记为缺失
基本统计(清洗后):
科目 均值 中位数 标准差 语文 77.5 78.0 12.1 数学 80.3 82.0 15.2 英语 79.4 78.0 10.3 偏科学生: - 孙八:数学 48 分,与英语(60)差距 12 分,与语文(55)差距 7 分,数学明显偏弱
第 3 步:检查 AI 的分析结果。重点核实:数据问题是否都被发现了?统计数字是否正确?建议是否合理?
主线任务:分析一份真实数据,生成分析报告
从以下数据集中选择一个(或使用自己的真实数据),完成一份完整的数据分析报告:
学业类:班级期末成绩数据(使用上方模拟数据)
生活类:自己过去一个月的消费账单,分析食品支出占比(恩格尔系数)
社会类:某城市不同年龄段的阅读偏好数据(可让 AI 生成模拟数据)
操作步骤:
- 将数据粘贴给 DeepSeek,要求进行数据清洗和基本统计(均值、中位数、标准差);
- 让 AI 生成各科成绩分布的可视化图表;
- 让 AI 识别成绩异常的学生并分析可能原因;
- 将分析结果整理为一份结构化的报告。
6.2 个性化方案定制
数据分析的终极目标不是生成图表,而是为具体的人提供具体的建议。
一、从”群体分析”到”个体方案”
6.1 节的数据分析侧重于群体层面的统计(如班级平均分、成绩分布)。但在实际应用中,我们往往需要根据个体数据生成个性化的方案——这正是 AI 擅长的领域。
核心思路:
个体数据 → AI 分析特征 → 匹配知识库 → 生成个性化方案以下通过两个跨学科融合案例来演示这一思路。
二、体育融合:“科学锻炼教练”
场景:根据学生的体测数据,生成个性化的训练计划。
实操演示:用 DeepSeek 生成个性化训练方案
第 1 步:收集体测数据。假设体测成绩如下:
身高:175cm,体重:78kg,BMI:25.5
1000 米跑:4 分 35 秒(及格线 4 分 32 秒)
引体向上:6 个(及格线 10 个)
立定跳远:2.15 米(良好)
坐位体前屈:8cm(及格)第 2 步:打开 DeepSeek,输入以下提示词:
你是一位运动科学专家。以下是一名大二男生的体测数据:
- 身高:175cm,体重:78kg,BMI:25.5
- 1000 米跑:4 分 35 秒(及格线 4 分 32 秒)
- 引体向上:6 个(及格线 10 个)
- 立定跳远:2.15 米(良好)
- 坐位体前屈:8cm(及格)
请完成:
1. 分析该生的体能优势和薄弱环节;
2. 制定一份为期 4 周的训练计划,重点提升薄弱项;
3. 每周训练 4 次,每次 45 分钟,标注强度等级;
4. 附上饮食建议和注意事项。第 3 步:查看 AI 输出,重点检查以下内容:
DeepSeek 输出示例(节选):
体能分析: - 优势:立定跳远达到良好,说明下肢爆发力较好 - 薄弱项:引体向上仅 6 个(差 4 个达标),上肢力量不足;1000 米跑超时 3 秒,心肺耐力需提升 - BMI 25.5 略偏高,建议适当控制体重
第 1 周训练计划(适应期):
日期 训练内容 时长 强度 周一 慢跑 20 分钟 + 俯卧撑 3×10 + 拉伸 45 min ★★☆ 周三 引体向上辅助训练 + 核心力量 45 min ★★☆ 周五 间歇跑(400m×4)+ 上肢力量 45 min ★★★ 周日 柔韧性训练 + 轻松慢跑 45 min ★☆☆
第 4 步:根据自身实际情况调整。AI 生成的方案是通用建议,可以追问细节:
第 1 周的引体向上辅助训练具体怎么做?
我目前只能做 6 个,请给出从 6 个提升到 10 个的渐进方案。AI 生成方案的关键要素:
表6-5 AI辅助个性化训练方案关键要素
| 要素 | 说明 |
|---|---|
| 现状评估 | 基于数据的客观分析,而非主观判断 |
| 目标设定 | 具体、可量化、有时间节点 |
| 分阶段计划 | 循序渐进,避免运动损伤 |
| 个性化调整 | 针对薄弱项重点训练 |
重要提醒:AI 生成的训练计划仅供参考。有运动损伤史或特殊健康状况的同学,应在专业体育教师指导下进行训练。
思辨时刻:数据之外的”人的温度”
AI 根据体测数据建议”每天跑 5 公里”,但如果这名学生今天心情极度低落,或者身体有轻微不适呢?数据看不到一个人此刻的状态。数据分析提供的是”一般情况下的最优解”,而人的决策需要考虑”此时此刻的具体处境”。无论未来从事什么职业——教师、护士、管理者——都要记住:数据是参考,对人的具体处境的体察才是决策的灵魂。
三、心理融合:“心灵成长伙伴”
场景:利用 AI 进行心理健康知识科普和情绪管理练习。
在进入具体操作之前,有必要先明确 AI 在心理辅助场景中的使用边界:
边界设定——AI 心理辅助的红线:
表6-6 AI心理辅助的使用边界
| 行为 | 性质 | 说明 |
|---|---|---|
| 用 AI 学习心理学知识 | ✅ 合理使用 | 相当于阅读科普书籍 |
| 用 AI 练习情绪管理技巧 | ✅ 合理使用 | 如正念练习、认知重构 |
| 用 AI 替代专业心理咨询 | ❌ 不可取 | AI 无法提供专业诊断和治疗 |
| 向 AI 倾诉严重心理困扰 | ❌ 应寻求专业帮助 | 请联系学校心理咨询中心或拨打心理援助热线 |
核心原则:AI 是心理健康”科普员”,不是”咨询师”。它可以帮助了解心理学知识、练习自我调节技巧,但不能替代专业的心理咨询和治疗。
提示词示例(情绪管理练习):
你是一位心理健康教育老师,擅长认知行为疗法(CBT)的科普。
一名学生反映最近考试压力很大,经常失眠、注意力不集中。
请完成:
1. 用通俗易懂的语言解释"考试焦虑"的心理机制;
2. 提供 3 个基于 CBT 的自我调节技巧,每个配一个练习步骤;
3. 设计一份"情绪日记"模板,帮助学生记录和管理情绪。数据伦理红线:谁有权把数据交给 AI?
当我们把同学的体测数据或心理测评结果粘贴给 AI 分析时,是否想过:这些数据的主人同意了吗?个人的身体指标、情绪状态、学业成绩都属于隐私数据。未经授权就将他人数据投喂给 AI,即使出发点是”帮忙分析”,实质上也是对隐私的侵犯。数据保护不是技术问题,而是对人的尊严的尊重——这是每一个数据使用者的职业底线。
拓展任务·体育融合:“科学锻炼教练”
收集自己的体测数据(或使用模拟数据),让 AI 生成一份个性化的 4 周训练计划,并记录第一周的执行情况。
拓展任务·心理融合:“心灵成长伙伴”
使用 AI 设计一份”考试周情绪管理工具包”,包含:情绪日记模板、3 个减压小练习、1 份作息建议。
阅读材料:推荐系统——淘宝”猜你喜欢”背后的逻辑
当打开淘宝,首页展示的商品几乎都是用户”可能感兴趣”的——这背后是推荐系统在工作。推荐系统的核心逻辑是:收集用户的行为数据(浏览、搜索、购买、收藏),构建”用户画像”(年龄、性别、消费偏好、价格敏感度),然后通过协同过滤、深度学习等算法,预测用户可能喜欢的商品并推送。
更进一步,推荐系统还会使用”交叉销售”策略——如果用户买了手机壳,它会推荐钢化膜;如果买了跑步鞋,它会推荐运动袜。这种”买了 A 的人通常也会买 B”的关联分析,其实就是数据驱动的个性化方案定制。
思考:推荐系统让购物更方便了,但它是否也在制造”信息茧房”——让人只看到自己想看的,而错过了更广阔的选择?
6.3 Python 数据分析初探(进阶选修)
本节面向有编程兴趣的同学。如果暂时不打算学习编程,可以跳过本节,不影响后续章节的学习。
写在前面:本节的目标不是让你”学会 Python”,而是让你体验一种思维方式——计算思维:把一个复杂问题拆解为”输入→处理→输出”的逻辑步骤。记住语法不重要,重要的是学会用自然语言描述需求,让 AI 帮你把逻辑翻译成代码。只要有清晰的逻辑,即使不会写代码,也能指挥 AI 完成数据分析任务。
一、为什么选择 Python?
Python 是数据分析和人工智能领域最主流的编程语言,原因在于:
语法简洁:接近自然语言,入门门槛低;
生态丰富:拥有 NumPy、Pandas、scikit-learn 等强大的数据科学库;
AI 友好:可以直接让 DeepSeek 帮忙编写和调试 Python 代码。
二、环境准备
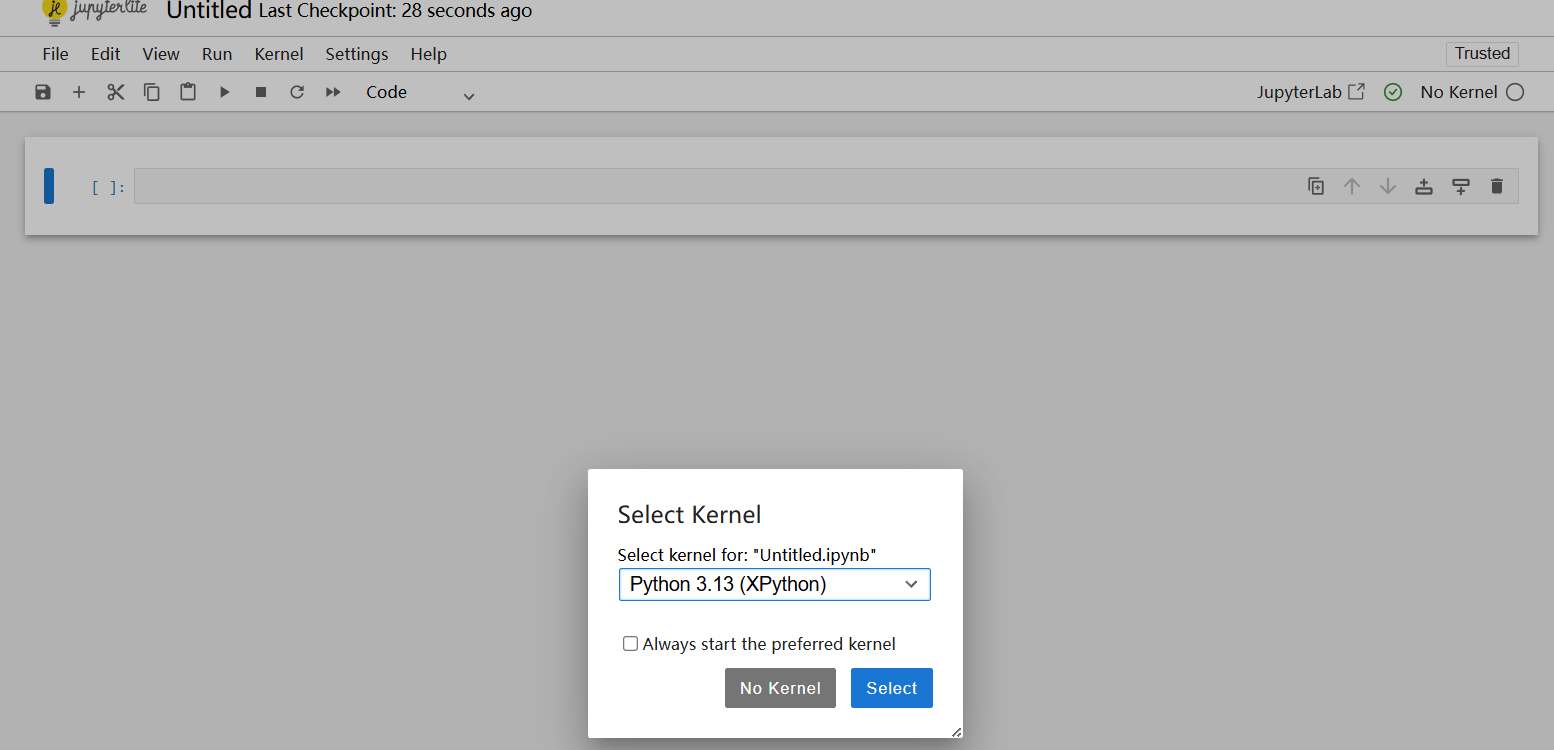
推荐使用 Jupyter 官方提供的在线环境(jupyter.org/try-jupyter),无需在本地安装任何软件,打开浏览器即可编写和运行 Python 代码。
操作步骤:
- 访问 https://jupyter.org/try-jupyter/,点击”Jupyter Notebook”;
- 在启动页面中选择内核 Python 3.13,新建一个 Notebook;
- 在代码单元格中输入 Python 代码,按
Shift + Enter运行。
三、NumPy 与 Pandas 基础
NumPy:高效的数值计算
import numpy as np
## 创建一组成绩数据
scores = np.array([78, 85, 92, 66, 73, 88, 95, 70, 82, 90])
print(f"平均分:{scores.mean():.1f}")
print(f"最高分:{scores.max()}")
print(f"最低分:{scores.min()}")
print(f"标准差:{scores.std():.1f}")Pandas:表格数据处理利器
import pandas as pd
## 读取 CSV 文件
df = pd.read_csv("成绩表.csv")
## 查看前 5 行
print(df.head())
## 按班级分组计算平均分
print(df.groupby("班级")["总分"].mean())
## 筛选不及格的学生
failed = df[df["总分"] < 60]
print(f"不及格人数:{len(failed)}")提示:不需要记住所有函数。遇到不会写的代码,直接用自然语言描述需求,让 DeepSeek 帮忙生成。例如:“用 Pandas 读取一个 CSV 文件,按班级分组统计各科平均分,并生成柱状图。”
四、Matplotlib:用 Python 画图表
Matplotlib 是 Python 中最常用的可视化库。配合 Pandas,可以用几行代码生成专业的数据图表。
实操演示:用 DeepSeek 生成可视化代码
假设想把 6.1 节的成绩数据画成柱状图。不需要记住 Matplotlib 的语法——直接告诉 DeepSeek 想要什么:
请用 Python 的 matplotlib 库,根据以下数据画一个柱状图:
- 科目:语文、数学、英语
- 均值:77.5、80.3、79.4
要求:中文标题"各科平均分对比",柱子用不同颜色,显示数值标签。DeepSeek 会生成类似以下代码:
import matplotlib.pyplot as plt
## 设置中文字体(Jupyter 在线环境)
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
subjects = ['语文', '数学', '英语']
means = [77.5, 80.3, 79.4]
colors = ['#FF6B6B', '#4ECDC4', '#45B7D1']
plt.figure(figsize=(8, 5))
bars = plt.bar(subjects, means, color=colors)
## 在柱子上方显示数值
for bar, val in zip(bars, means):
plt.text(bar.get_x() + bar.get_width()/2, bar.get_height() + 0.5,
f'{val}', ha='center', fontsize=12)
plt.title('各科平均分对比', fontsize=16)
plt.ylabel('平均分')
plt.ylim(70, 85)
plt.show()代码解读:
plt.bar()画柱状图,color参数控制颜色;plt.text()在柱子上方添加数值标签;plt.show()显示图表。
将这段代码复制到 Jupyter Notebook 中运行,就能看到一张带有中文标题和数值标签的柱状图。
小贴士:如果运行时中文显示为方块,说明在线环境缺少中文字体。可以将字体设置改为
plt.rcParams['font.sans-serif'] = ['Noto Sans CJK SC', 'SimHei', 'DejaVu Sans'],或在本地安装 Python 环境运行。
五、scikit-learn:机器学习初体验
scikit-learn 是 Python 中最常用的机器学习库。以下用一个简单的例子演示”线性回归”——根据学习时长预测考试成绩。
from sklearn.linear_model import LinearRegression
import numpy as np
## 训练数据:学习时长(小时)与考试成绩
hours = np.array([2, 3, 4, 5, 6, 7, 8]).reshape(-1, 1)
scores = np.array([55, 62, 68, 75, 80, 85, 90])
## 训练模型
model = LinearRegression()
model.fit(hours, scores)
## 预测:学习 5.5 小时能考多少分?
predicted = model.predict([[5.5]])
print(f"预测成绩:{predicted[0]:.1f} 分")
print(f"每多学 1 小时,成绩约提升 {model.coef_[0]:.1f} 分")代码解读:
LinearRegression()创建一个线性回归模型;model.fit()用已有数据”训练”模型,让它学习学习时长与成绩之间的关系;model.predict()用训练好的模型进行预测。
这就是机器学习的基本范式:用数据训练模型,用模型做预测。
▲ 进阶挑战:用 Python 分析真实教育数据集
- 从公开数据集网站(如 Kaggle)下载一份教育相关的数据集;
- 使用 Pandas 进行数据清洗和探索性分析;
- 使用 scikit-learn 训练一个分类模型(如预测学生是否会通过考试);
- 将分析过程和结论整理为一份 Jupyter Notebook 报告。
提示:整个过程中,可以随时将代码报错信息粘贴给 DeepSeek,让它帮助调试。AI 辅助编程是当前最高效的学习方式之一。
本章小结
本章围绕”让数字开口说话”这一目标,从 AI 辅助数据分析基础讲起,延伸到个性化方案定制,最后为有编程兴趣的读者提供了 Python 数据分析的入门路径。数据不是冰冷的数字,而是理解世界的”第二语言”。
| 小节 | 核心内容 | 关键概念 |
|---|---|---|
| 6.1 数据分析基础 | 利用 AI 辅助 Excel 操作,完成数据清洗、公式生成、可视化图表和分析报告 | Excel 公式、数据清洗、数据可视化 |
| 6.2 个性化方案定制 | 基于个体数据(如体测成绩、性格测试)用 AI 生成针对性的改进方案 | 个性化分析、方案定制 |
| 6.3 Python 数据分析初探 | 体验用 Pandas 和 Scikit-learn 进行数据分析的计算思维方式(进阶选修) | Python、Pandas、计算思维 |
只有数据没有洞察,就等于守着金矿要饭。掌握 AI 辅助数据分析的能力,便能从数据中发现规律、支撑决策。下一章将更进一步,学习如何搭建专属的 AI 智能体。
第六章 实践与练习
数据不说谎,但说谎的人会利用数据。学会数据分析,是为了看清真相。
一、选择题
- 以下哪个统计指标最不容易受极端值影响?
- A. 均值
- B. 中位数
- C. 最大值
- D. 总和
- 数据清洗时,发现某学生成绩为 999 分,最合理的处理方式是:
- A. 直接删除该学生的所有数据
- B. 将 999 改为 0 分
- C. 标记为异常值,联系数据源核实后再处理
- D. 用全班平均分替换
- 想要展示”各班级期末成绩的分布情况”,最合适的图表类型是:
- A. 饼图
- B. 折线图
- C. 箱线图
- D. 散点图
- AI 生成的个性化训练计划,使用前最需要注意的是:
- A. 计划的排版是否美观
- B. 是否结合个人实际情况并咨询专业人士
- C. AI 使用的是哪个模型
- D. 生成速度是否够快
二、简答题
请解释”均值”和”中位数”的区别,并举例说明在什么情况下中位数比均值更能反映数据的真实情况。
AI 可以根据个人数据生成个性化方案(如训练计划、学习计划),但为什么说这些方案”仅供参考”?请从数据准确性和专业判断两个角度分析。
三、实操题
数据分析报告:收集所在班级某次考试的成绩数据(或使用模拟数据),粘贴给 DeepSeek,要求完成数据清洗、基本统计分析和可视化图表生成。将 AI 的输出整理为一份完整的分析报告。
个性化方案:收集自己的体测数据(或使用模拟数据),让 DeepSeek 生成一份 4 周训练计划。要求:检查方案的合理性,并针对至少一个细节进行追问优化。
(进阶)Python 可视化:在 Jupyter 在线环境(jupyter.org/try-jupyter)中,使用 DeepSeek 帮忙编写 Python 代码,将一组成绩数据绘制为柱状图和折线图。记录与 DeepSeek 的对话过程(提示词和输出)。
参考答案(选择题):1-B 2-C 3-C 4-B
四、进阶挑战:我的量化生活
背景:量化自我(Quantified Self)是一种生活方式。
任务:记录你一周的手机屏幕使用时间(Screen Time)。数据列:日期、总时长、最常用 App、心情评分(1-10)。
隐私提示:本任务使用的是你自己的个人数据。在把数据输入 AI 时,无需填写真实姓名,用”我”代替即可。不要在 AI 对话中输入手机号、账号密码等敏感信息。
操作:
- 把数据录入 Excel。
- 把数据喂给 AI,提问:“分析我的手机使用习惯和心情之间有关系吗?”“预测一下,如果我下周每天少玩 1 小时手机,心情评分会如何变化?”
- 让 AI 生成一份”数字排毒计划”。
五、延伸阅读
- 书籍:《赤裸裸的统计学》 [8] —— 统计学入门神作,通俗易懂
- 网站:Kaggle —— 全球最大的数据科学社区,上面有无数有趣的数据集(如泰坦尼克号、房价预测)